Incident Report: Inadvertent Private Repository Disclosure
On Thursday, October 20th, a bug in GitHub’s system exposed a small amount of user data via Git pulls and clones. In total, 156 private repositories of GitHub.com users were…
On Thursday, October 20th, a bug in GitHub’s system exposed a small amount of user data via Git pulls and clones. In total, 156 private repositories of GitHub.com users were affected (including one of GitHub’s). We have notified everyone affected by this private repository disclosure, so if you have not heard from us, your repositories were not impacted and there is no ongoing risk to your information.
This was not an attack, and no one was able to retrieve vulnerable data intentionally. There was no outsider involved in exposing this data; this was a programming error that resulted in a small number of Git requests retrieving data from the wrong repositories.
Regardless of whether or not this incident impacted you specifically, we want to sincerely apologize. It’s our responsibility not only to keep your information safe but also to protect the trust you have placed in us. GitHub would not exist without your trust, and we are deeply sorry that this incident occurred.
Below is the technical analysis of our investigation, including a high-level overview of the incident, how we mitigated it, and the specific measures we are taking to safeguard against incidents like this from happening in the future.
High-level overview
In order to speed up unicorn worker boot times, and simplify the post-fork boot code, we applied the following buggy patch:

The database connections in our rails application are split into three pools: a read-only group, a group used by Spokes (our distributed Git back-end), and the normal Active Record connection pool. The read-only group and the Spokes group are managed manually, by our own connection handling code. This meant the pool was shared between all child processes of the rails application when running using the change. The new line of code disconnected only ConnectionPool objects that are managed by Active Record, whereas the previous snippet would disconnect all ConnectionPool objects held in memory.
The impact of this bug for most queries was a malformed response, which errored and caused a near immediate rollback. However, a very small percentage of the queries responses were interpreted as legitimate data in the form of the file server and disk path where repository data was stored. Some repository requests were routed to the location of another repository. The application could not differentiate these incorrect query results from legitimate ones, and as a result, users received data that they were not meant to receive.
When properly functioning, the system works as sketched out roughly below. However, during this failure window, the MySQL response in step 4 was returning malformed data that would end up causing the git proxy to return data from the wrong file server and path.
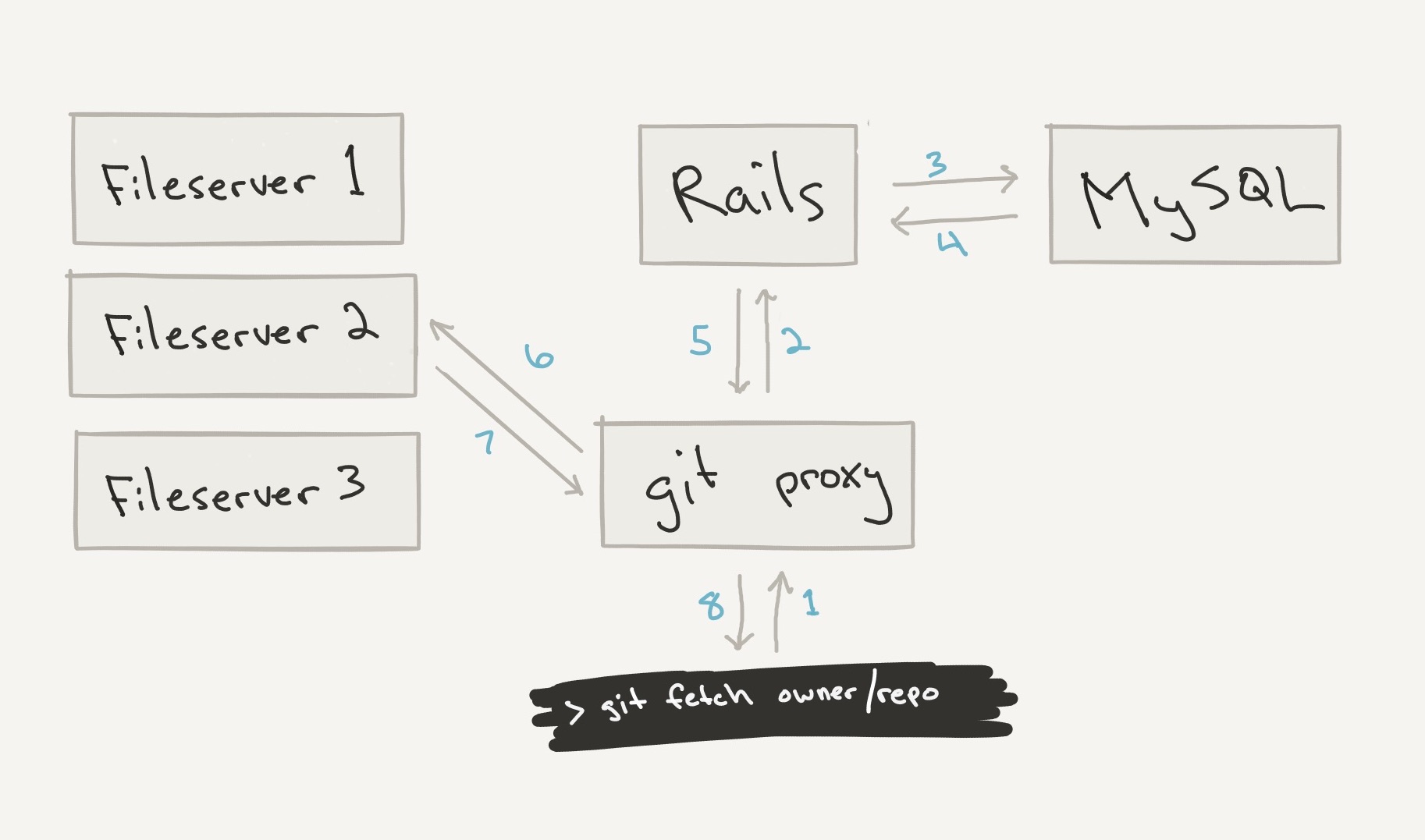
Our analysis of the ten-minute window in question uncovered:
- 17 million requests to our git proxy tier, most of which failed with errors due to the buggy deploy
- 2.5 million requests successfully reached git-daemon on our file server tier
- Of the 2.5 million requests that reached our file servers, the vast majority were “already up to date” no-op fetches
- 40,000 of the 2.5 million requests were non-empty fetches
- 230 of the 40,000 non-empty requests were susceptible to this bug and served incorrect data
- This represented 0.0013% of the total operations at the time
Deeper analysis and forensics
After establishing the effects of the bug, we set out to determine which requests were affected in this way for the duration of the deploy. Normally, this would be an easy task, as we have an in-house monitor for Git that logs every repository access. However, those logs contained some of the same faulty data that led to the misrouted requests in the first place. Without accurate usernames or repository names in our primary Git logs, we had to turn to data that our git proxy and git-daemon processes sent to syslog. In short, the goal was to join records from the proxy, to git-daemon, to our primary Git logging, drawing whatever data was accurate from each source. Correlating records across servers and data sources is a challenge because the timestamps differ depending on load, latency, and clock skew. In addition, a given Git request may be rejected at the proxy or by git-daemon before it reaches Git, leaving records in the proxy logs that don’t correlate with any records in the git-daemon or Git logs.
Ultimately, we joined the data from the proxy to our Git logging system using timestamps, client IPs, and the number of bytes transferred and then to git-daemon logs using only timestamps. In cases where a record in one log could join several records in another log, we considered all and took the worst-case choice. We were able to identify cases where the repository a user requested, which was recorded correctly at our git proxy, did not match the repository actually sent, which was recorded correctly by git-daemon.
We further examined the number of bytes sent for a given request. In many cases where incorrect data was sent, the number of bytes was far larger than the on-disk size of the repository that was requested but instead closely matched the size of the repository that was sent. This gave us further confidence that indeed some repositories were disclosed in full to the wrong users.
Although we saw over 100 misrouted fetches and clones, we saw no misrouted pushes, signaling that the integrity of the data was unaffected. This is because a Git push operation takes place in two steps: first, the user uploads a pack file containing files and commits. Then we update the repository’s refs (branch tips) to point to commits in the uploaded pack file. These steps look like a single operation from the user’s point of view, but within our infrastructure, they are distinct. To corrupt a Git push, we would have to misroute both steps to the same place. If only the pack file is misrouted, then no refs will point to it, and git fetch operations will not fetch it. If only the refs update is misrouted, it won’t have any pack file to point to and will fail. In fact, we saw two pack files misrouted during the incident. They were written to a temporary directory in the wrong repositories. However, because the refs-update step wasn’t routed to the same incorrect repository, the stray pack files were never visible to the user and were cleaned up (i.e., deleted) automatically the next time those repositories performed a “git gc” garbage-collection operation. So no permanent or user-visible effect arose from any misrouted push.
A misrouted Git pull or clone operation consists of several steps. First, the user connects to one of our Git proxies, via either SSH or HTTPS (we also support git-protocol connections, but no private data was disclosed that way). The user’s Git client requests a specific repository and provides credentials, an SSH key or an account password, to the Git proxy. The Git proxy checks the user’s credentials and confirms that the user has the ability to read the repository he or she has requested. At this point, if the Git proxy gets an unexpected response from its MySQL connection, the authentication (which user is it?) or authorization (what can they access?) check will simply fail and return an error. Many users were told during the incident that their repository access “was disabled due to excessive resource use.”
In the operations that disclosed repository data, the authentication and authorization step succeeded. Next, the Git proxy performs a routing query to see which file server the requested repository is on, and what its file system path on that server will be. This is the step where incorrect results from MySQL led to repository disclosures. In a small fraction of cases, two or more routing queries ran on the same Git proxy at the same time and received incorrect results. When that happened, the Git proxy got a file server and path intended for another request coming through that same proxy. The request ended up routed to an intact location for the wrong repository. Further, the information that was logged on the repository access was a mix of information from the repository the user requested and the repository the user actually got. These corrupted logs significantly hampered efforts to discover the extent of the disclosures.
Once the Git proxy got the wrong route, it forwarded the user’s request to git-daemon and ultimately Git, running in the directory for someone else’s repository. If the user was retrieving a specific branch, it generally did not exist, and the pull failed. But if the user was pulling or cloning all branches, that is what they received: all the commits and file objects reachable from all branches in the wrong repository. The user (or more often, their build server) might have been expecting to download one day’s commits and instead received some other repository’s entire history.
Users who inadvertently fetched the entire history of some other repository, surprisingly, may not even have noticed. A subsequent “git pull” would almost certainly have been routed to the right place and would have corrected any overwritten branches in the user’s working copy of their Git repository. The unwanted remote references and tags are still there, though. Such a user can delete the remote references, run “git remote prune origin,” and manually delete all the unwanted tags. As a possibly simpler alternative, a user with unwanted repository data can delete that whole copy of the repository and “git clone” it again.
Next steps
To prevent this from happening again, we will modify the database driver to detect and only interpret responses that match the packet IDs sent by the database. On the application side, we will consolidate the connection pool management so that Active Record’s connection pooling will manage all connections. We are following this up by upgrading the application to a newer version of Rails that doesn’t suffer from the “connection reuse” problem.
We will continue to analyze the events surrounding this incident and use our investigation to improve the systems and processes that power GitHub. We consider the unauthorized exposure of even a single private repository to be a serious failure, and we sincerely apologize that this incident occurred.
Written by

Related posts

GitHub availability report: June 2026
In June, we experienced six incidents that resulted in degraded performance across GitHub services.

Q1 2026 Innovation Graph update: Open source collaboration is accelerating worldwide
New Innovation Graph data shows global developer communities growing faster than ever, with collaboration reaching new highs across many economies.
GitHub joins coalition advocating for fixes to California AI Transparency Act to protect open source
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.