Building resilience in Spokes
Spokes is the replication system for the file servers where we store over 38 million Git repositories and over 36 million gists.It keeps at least three copies of every repository…
Spokes is the replication system for the file servers where we store over 38 million Git repositories and over 36 million gists.It keeps at least three copies of every repository and every gist so that we can provide durable, highly available access to content even when servers and networks fail. Spokes uses a combination of Git and rsync to replicate, repair, and rebalance repositories.
What is Spokes?
Before we get into the topic at hand—building resilience—we have a new name to announce: DGit is now Spokes.
Earlier this year, we announced “DGit” or “Distributed Git,” our application-level replication system for Git. We got feedback that the name “DGit” wasn’t very distinct and could cause confusion with the Git project itself. So we have decided to rename the system Spokes.
Defining resilience
In any system or service, there are two key ways to measure resilience: availability and durability. A system’s availability is the fraction of the time it can provide the service it was designed to provide. Can it serve content? Can it accept writes? Availability can be partial, complete, or degraded: is every repository available? Are some repositories—or whole servers—slow?
A system’s durability is its resistance to permanent data loss. Once the system has accepted a write—a push, a merge, an edit through the website, new-repository creation, etc.—it should never corrupt or revert that content. The key here is the moment that the system accepts the write: how many copies are stored, and where? Enough copies must be stored for us to believe with some very high probability that the write will not be lost.
A system can be durable but not available. For example, if a system can’t make the minimum required number of copies of an incoming write, it might refuse to accept writes. Such a system would be temporarily unavailable for writing, while maintaining the promise not to lose data. Of course, it is also possible for a system to be available without being durable, for example, by accepting writes whether or not they can be committed safely.
Readers may recognize this as related to the CAP Theorem. In short, a system can satisfy at most two of these three properties:
- consistency: all nodes see the same data
- availability: the system can satisfy read and write requests
- partition tolerance: the system works even when nodes are down or
unable to communicate
Spokes puts the highest priority on consistency and partition tolerance. In worst-case failure scenarios, it will refuse to accept writes that it cannot commit, synchronously, to at least two replicas.
Availability
Spokes’s availability is a function of the availability of underlying servers and networks, and of our ability to detect and route around server and network problems.
Individual servers become unavailable pretty frequently. Since rolling out Spokes this past spring, we have had individual servers crash due to a kernel deadlock and faulty RAM chips. Sometimes servers provide degraded service due to lesser hardware faults or high system load. In all cases, Spokes must detect the problem quickly and route around it. Each repository is replicated on three servers, so there’s almost always an up-to-date, available replica to route to even if one server is offline. Spokes is more than the sum of its individually-failure-prone parts.
Detecting problems quickly is the first step. Spokes uses a combination of heartbeats and real application traffic to determine when a file server is down. Using real application traffic is key for two reasons. First, heartbeats learn and react slowly. Each of our file servers handles a hundred or more incoming requests per second. A heartbeat that happens once per second would learn about a failure only after a hundred requests had already failed. Second, heartbeats test only a subset of the server’s functionality: for example, whether or not the server can accept a TCP connection and respond to a no-op request. But what if the failure mode is more subtle? What if the Git binary is corrupt? What if disk accesses have stalled? What if all authenticated operations are failing? No-ops can often succeed when real traffic will fail.
So Spokes watches for failures during the processing of real application traffic, and it marks a node as offline if too many requests fail. Of course, real requests do fail sometimes. Someone can try to read a branch that has already been deleted, or try to push to a branch they don’t have access to, for example. So Spokes only marks the node offline if three requests fail in a row. That sometimes marks perfectly healthy nodes offline—three requests can fail in a row just by random chance—but not often, and the penalty for it is not large.
Spokes uses heartbeats, too, but not as the primary failure-detection mechanism. Instead, heartbeats have two purposes: polling system load and providing the all-clear signal after a node has been marked as offline. As soon as a heartbeat succeeds, the node is marked as online again. If the heartbeat succeeds despite ongoing server problems (retrieving system load is almost a no-op), the node will get marked offline again after three more failed requests.
So Spokes detects that a node is down within about three failed operations. That’s still three failed operations too many! For clean failures—connections refused or timeouts—all operations know how to try the next host. Remember, Spokes has three or more copies of every repository. A routing query for a repository returns not one server, but a list of three (or so) up-to-date replicas, sorted in preference order. If an operation attempted on the first-choice replica fails, there are usually two other replicas to try.
A graph of operations (here, remote procedure calls, or RPCs) failed over from one server to another clearly shows when a server is offline. In this graph, a single server is unavailable for about 1.5 hours; during this time, many thousands of RPC operations are redirected to other servers. This graph is the single best detector the Spokes team has for discovering misbehaving servers.
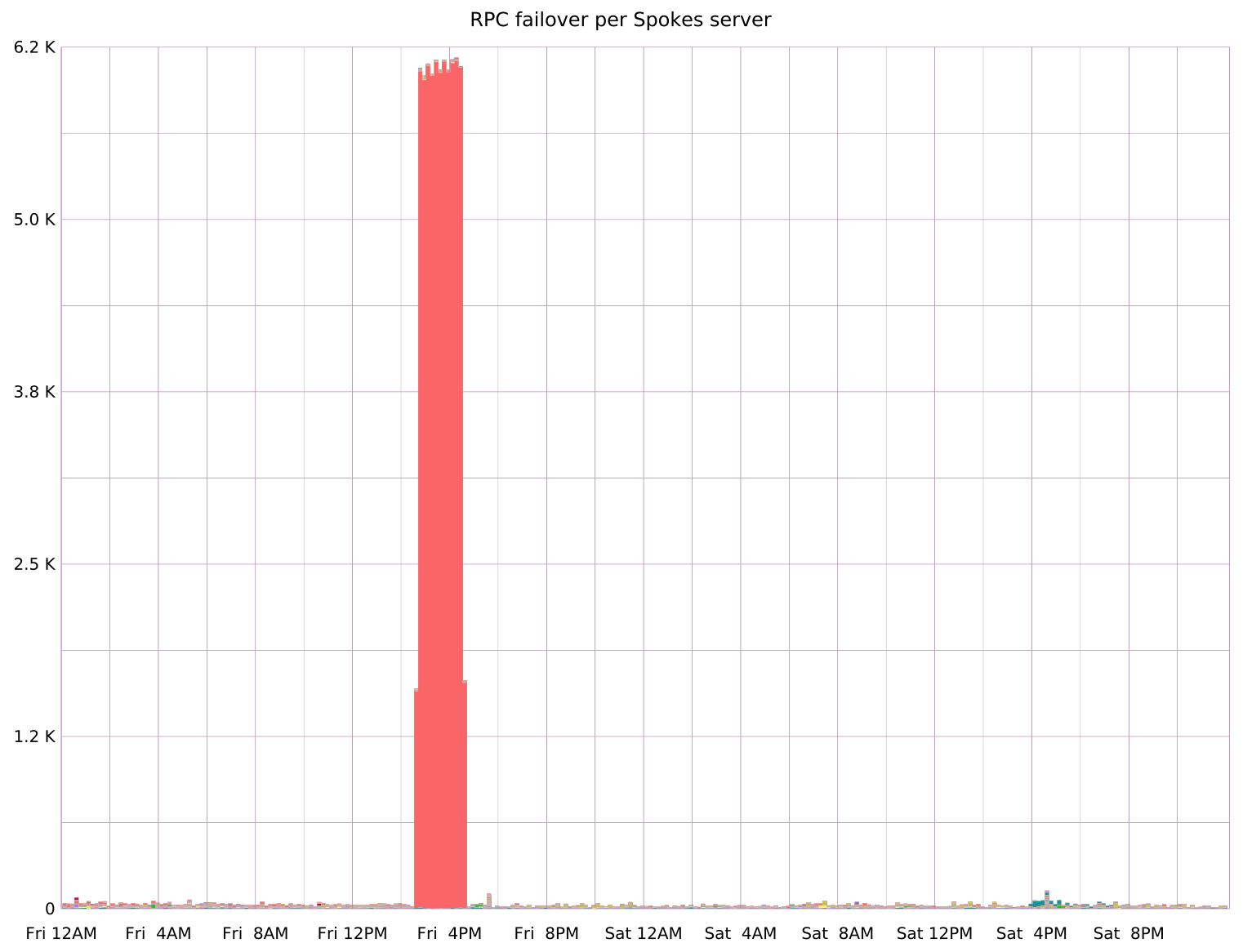
Spokes’s node-offline detection is only advisory—i.e., only an optimization. A node that has had three failures in a row just gets moved to the end of the preference order for all read operations, rather than removed from the list of replicas. It’s better for Spokes to try a probably-offline replica last, than to not try it at all.
This failure detector works well for server failures: when a server is overloaded or offline, operations to it will fail. Spokes detects those failures and temporarily stops directing traffic to the failed server until a heartbeat succeeds. However, failures of networks and application (Rails) servers are much messier. A given file server can appear to be offline to just a subset of the application servers, or one bad application server can spuriously determine that every file server is offline. So Spokes’s failure detection is actually MxN: each application server keeps its own list of which file servers are offline, or not. If we see many application servers marking a single file server as offline, then it probably is. If we see a single application server marking many file servers offline, then we’ve learned about a fault on that application server, instead.
The figure below illustrates the MxN nature of failure detection and shows in red which failure detectors are true if a single file server, dfs4, is offline.
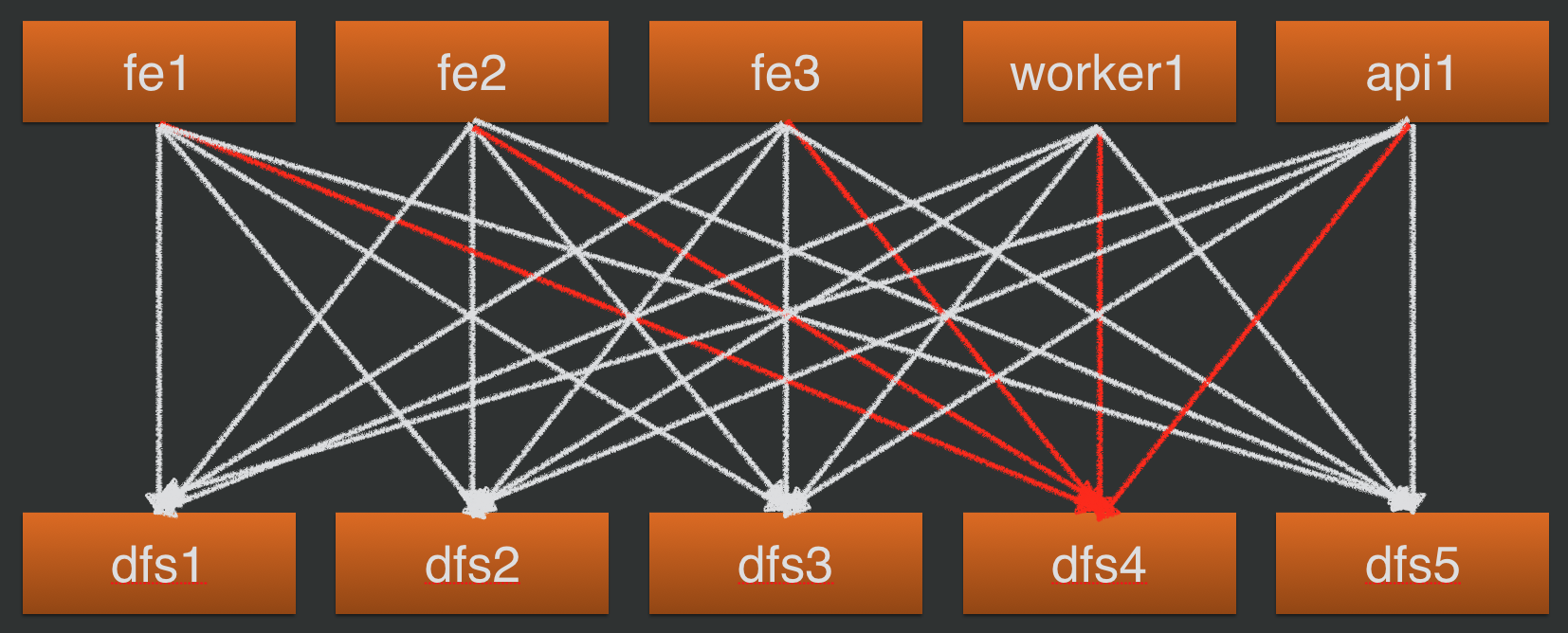
In one recent incident, a single front-end application server in a staging environment lost its ability to resolve the DNS names of the file servers. Because it couldn’t reach the file servers to send them RPC operations or heartbeats, it concluded that every file server was offline. But that incorrect determination was limited to that one application server; all other application servers worked normally. So the flaky application server was immediately obvious in the RPC-failover graphs, and no production traffic was affected.
Durability
Sometimes, servers fail. Disks can fail; RAID controllers can fail; even entire servers or entire racks can fail. Spokes provides durability for repository data even in the face of such adversity.
The basic building block of durability, like availability, is replication. Spokes keeps at least three copies of every repository, wiki, and gist, and those copies are in different racks. No updates to a repository—pushes, renames, edits to a wiki, etc.—are accepted unless a strict majority of the replicas can apply the change and get the same result.
Spokes needs just one extra copy to survive a single-node failure. So why a majority? It’s possible, even common, for a repository to get multiple writes at roughly the same time. Those writes might conflict: one user might delete a branch while another user pushes new commits to that same branch, for example. Conflicting writes must be serialized—that is, they have to be applied (or rejected) in the same order on every replica, so every replica gets the same result. The way Spokes serializes writes is by ensuring that every write acquires an exclusive lock on a majority of replicas. It’s impossible for two writes to acquire a majority at the same time, so Spokes eliminates conflicts by eliminating concurrent writes entirely.
If a repository exists on exactly three replicas, then a successful write on two replicas constitutes both a durable set, and a majority. If a repository has four or five replicas, then three are required for a majority.
In contrast, many other replication and consensus protocols have a single primary copy at any moment. The order that writes arrive at the primary copy is the official order, and all other replicas must apply writes in that order. The primary is generally designated manually, or automatically using an election protocol. Spokes simply skips that step and treats every write as an election—selecting a winning order and outcome directly, rather than a winning server that dictates the write order.
Any write in Spokes that can’t be applied identically at a majority of replicas gets reverted from any replica where it was applied. In essence, every write operation goes through a voting protocol, and any replicas on the losing side of the vote are marked as unhealthy—unavailable for reads or writes—until they can be repaired. Repairs are automatic and quick. Because a majority agreed either to accept or to roll back the update, there are still at least two replicas available to continue accepting both reads and writes while the unhealthy replica is
repaired.
To be clear, disagreements and repairs are exceptional cases. GitHub accepts many millions of repository writes each day. On a typical day, a few dozen writes will result in non-unanimous votes, generally because one replica was particularly busy, the connection to it timed out, and the other replicas voted to move on without it. The lagging replica almost always recovers within a minute or two, and there is no user-visible impact on the repository’s availability.
Rarer still are whole-disk and whole-server failures, but they do happen. When we have to remove an entire server, there are suddenly hundreds of thousands of repositories with only two copies, instead of three. This, too, is a repairable condition. Spokes checks periodically to see if every repository has the desired number of replicas; if not, more replicas are created. New replicas can be created anywhere, and they can be copied from wherever the surviving two copies of each repository are. Hence, repairs after a server failure are N-to-N. The larger the file server cluster, the faster it can recover from a single-node failure.
Clean shutdowns
As described above, Spokes can deal quickly and transparently with a server going offline or even failing permanently. So, can we use that for planned maintenance, when we need to reboot or retire a server? Yes and no.
Strictly speaking, we can reboot a server with sudo reboot, and we can retire it just by unplugging it. But there are subtle disadvantages to doing so, so we have more careful mechanisms, reusing a lot of the same logic that would respond to a crash or a failure.
Simply rebooting a server does not affect future read and write operations, which will be transparently directed to other replicas. It doesn’t affect in-progress write operations, either, as those are happening on all replicas, and the other two replicas can easily vote to proceed without the server we’re rebooting. But a reboot does break in-progress read operations. Most of those reads—e.g., fetching a README to display on a repository’s home page—are quick and will complete while the server shuts down gracefully. But some reads, particularly clones of large repositories, take minutes or hours to complete, depending on the speed of the end user’s network. Breaking these is, well, rude. They can be restarted on another replica, but all progress up to that point would be lost.
Hence, rebooting a server intentionally in Spokes begins with a quiescing period. While a server is quiescing, it is marked as offline for the purposes of new read operations, but existing read operations, including clones, are allowed to finish. Quiescing can take anywhere from a few seconds to many hours, depending on which read operations are active on the server that is getting rebooted.
Perhaps surprisingly, write operations are sent to servers as usual, even while they quiesce. That’s because write operations run on all replicas, so one replica can drop out at any time without user-visible impact. Also, that replica would fall arbitrarily far behind if it didn’t receive writes while quiescing, creating a lot of catch-up load when it is finally brought fully back online.
We don’t perform “chaos monkey” testing on the Spokes file servers, for the same reasons we prefer to quiesce them before rebooting them: to avoid interrupting long-running reads. That is, we do not reboot them randomly just to confirm that sudden, single-node failures are still (mostly) harmless.
Instead of “chaos monkey” testing, we perform rolling reboots as needed, which accomplish roughly the same testing goals. When we need to make some change that requires a reboot—e.g., changing kernel or filesystem parameters, or changing BIOS settings—we quiesce and reboot each server. Racks serve as availability zones[1], so we quiesce entire racks at a time. As servers in a given rack finish quiescing—i.e., complete all outstanding read operations—we reboot up to five of them at a time. When a whole rack is finished, we move on to the next rack.
Below is a graph showing RPC operations failed over during a rolling reboot. Each server gets a different color. Values are stacked, so the tallest spike shows a moment where eight servers were rebooting at once. The large block of light red shows where one server did not reboot cleanly and was offline for over two hours.
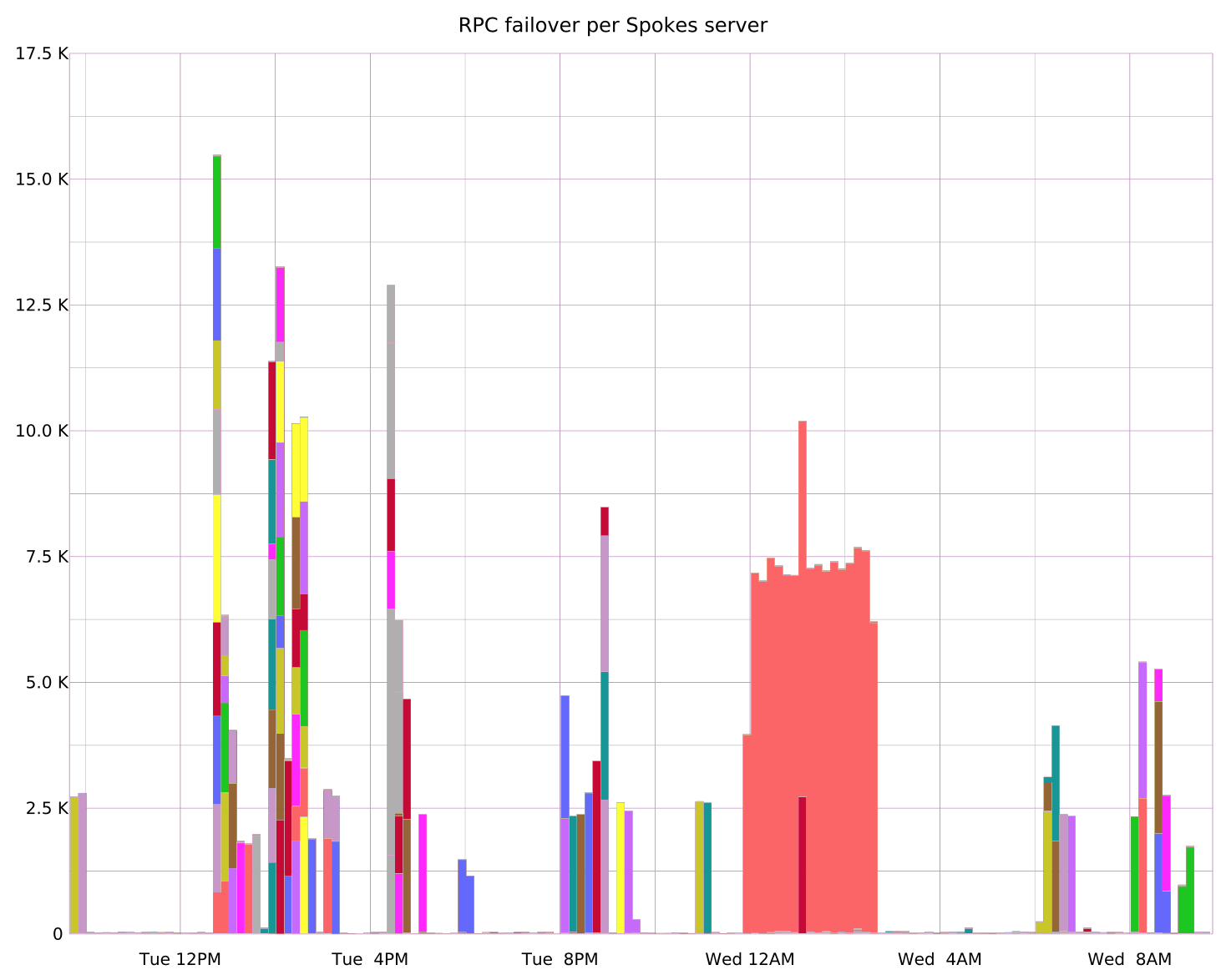
Retiring a server by simply unplugging it has the same disadvantages as unplanned reboots, and more. In addition to disrupting any in-progress read operations, it creates several hours of additional risk for all the repositories that used to be hosted on the server. When a server disappears suddenly, all of the repositories formerly on it are now down to two copies. Two copies are enough to perform any read or write operation, but two copies aren’t enough to tolerate an additional failure. In other words, removing a server without warning increases the probability of rejecting write operations later that same day. We’re in the business of keeping that probability to a minimum.
So instead, we prepare a server for retirement by removing it from the count of active replicas for any repository. Spokes can still use that server for both read and write operations. But when it asks if all repositories have enough replicas, suddenly some of them—the ones on the retiring server—will say no, and more replicas will be created. These repairs proceed exactly as if the server had just disappeared, except that now the server remains available in case some other server fails.
Conclusions
Availability is important, and durability is more important still. Availability is a measure of what fraction of the time a service responds to requests. Durability is a measure of what fraction of committed data a service can faithfully store.
Spokes keeps at least three replicas of every repository, to provide both availability and durability. Three replicas means that one server can fail with no user-visible effect. If two servers fail, Spokes can provide full access for most repositories and read-only access to repositories that had two of their replicas on the two failing servers.
Spokes does not accept writes to a repository unless a majority of replicas—and always at least two—can commit the write and produce the same resulting repository state. That requirement provides consistency by ensuring the same write ordering on all replicas. It also provides durability in the face of single-server failures by storing every committed write in at least two places.
Spokes has a failure detector, based on monitoring live application traffic, that determines when a server is offline and routes around the problem. Finally, Spokes has automated repairs for recovering quickly when a disk or server fails permanently.
1. Treating racks as availability zones means we place repository replicas so that no repository has two replicas within the same rack. Hence, we can lose an entire rack of servers and not affect the availability or durability of any of the repositories hosted on them. We chose racks as availability zones because several important failure modes, especially related to power and networking, can affect entire racks of servers at a time.
Written by

Related posts
Better tools made Copilot code review worse. Here’s how we actually improved it.
How migrating Copilot code review to shared Unix-style code exploration tools reduced review cost by reshaping agent workflows around pull request evidence.
Automating cross-repo documentation with GitHub Agentic Workflows
Explore how the Aspire team turns merged product changes into SME-reviewed docs pull requests, closing the gap between release and documentation.

From latency to instant: Modernizing GitHub Issues navigation performance
How the GitHub Issues team used client-side caching, smart prefetching, and service workers to make navigation feel instant.