gh-ost: GitHub’s online schema migration tool for MySQL
Today we are announcing the open source release of gh-ost: GitHub’s triggerless online schema migration tool for MySQL. gh-ost has been developed at GitHub in recent months to answer a…
Today we are announcing the open source release of gh-ost: GitHub’s triggerless online schema migration tool for MySQL.
gh-ost has been developed at GitHub in recent months to answer a problem we faced with ongoing, continuous production changes requiring modifications to MySQL tables. gh-ost changes the existing online table migration paradigm by providing a low impact, controllable, auditable, operations friendly solution.
MySQL table migration is a well known problem, and has been addressed by online schema change tools since 2009. Growing, fast-paced products often require changes to database structure. Adding/changing/removing columns and indexes etc., are blocking operations with the default MySQL behavior. We conduct such schema changes multiple times per day and wish to minimize user facing impact.
Before illustrating gh-ost, let’s address the existing solutions and the reasoning for embarking on a new tool.
Online schema migrations, existing landscape
Today, online schema changes are made possible via these three main options:
- Migrate the schema on a replica, clone/apply on other replicas, promote refactored replica as new master
- Use MySQL’s Online DDL for InnoDB
- Use a schema migration tool. Most common today are
pt-online-schema-changeand Facebook’s OSC; also found areLHMand the originaloak-online-alter-tabletool.
Other options include Rolling Schema Upgrade with Galera Cluster, and otherwise non-InnoDB storage engines. At GitHub we use the common master-replicas architecture and utilize the reliable InnoDB engine.
Why have we decided to embark on a new solution rather than use either of the above? The existing solutions are all limited in their own ways, and the below is a very brief and generalized breakdown of some of their shortcomings. We will drill down more in-depth about the shortcomings of the trigger-based online schema change tools.
- Replica migration makes for an operational overhead, which requires larger host count, longer delivery times and more complex management. Changes are applied explicitly on specific replicas or on sub-trees of the topology. Such considerations as hosts going down, host restores from an earlier backup, newly provisioned hosts, all require a strict tracking system for per-host changes. A change might require multiple iterations, hence more time. Promoting a replica to master incurs a brief outage. Multiple changes going at once are more difficult to coordinate. We commonly deploy multiple schema changes per day and wish to be free of the management overhead, while we recognize this solution to be in use.
-
MySQL’s Online DDL for InnoDB is only “online” on the server on which it is invoked. Replication stream serializes the
alterwhich causes replication lag. An attempt to run it individually per-replica results in much of the management overhead mentioned above. The DDL is uninterruptible; killing it halfway results in long rollback or with data dictionary corruption. It does not play “nice”; it cannot throttle or pause on high load. It is a commitment into an operation that may exhaust your resources. -
We’ve been using
pt-online-schema-changefor years. However as we grew in volume and traffic, we hit more and more problems, to the point of considering many migrations as “risky operations”. Some migrations would only be able to run during off-peak hours or through weekends; others would consistently cause MySQL outage.
All existing online-schema-change tools utilize MySQLtriggersto perform the migration, and therein lies a few problems.
What’s wrong with trigger-based migrations?
All online-schema-change tools operate in similar manner: they create a ghost table, in the likeness of your original table, migrate that table while empty, slowly and incrementally copy data from your original table to the ghost table, meanwhile propagating ongoing changes (any INSERT, DELETE, UPDATE applied to your table) to the ghost table. When the tool is satisfied the tables are in sync, it replaces your original table with the ghost table.
Tools like pt-online-schema-change, LHM and oak-online-alter-table use a synchronous approach, where each change to your table translates immediately, utilizing same transaction space, to a mirrored change on the ghost table. The Facebook tool uses an asynchronous approach of writing changes to a changelog table, then iterating that and applying changes onto the ghost table. All of these tools use triggers to identify those ongoing changes to your table.
Triggers are stored routines which are invoked on a per-row operation upon INSERT, DELETE, UPDATE on a table. A trigger may contain a set of queries, and these queries run in the same transaction space as the query that manipulates the table. This makes for an atomicy of both the original operation on the table and the trigger-invoked operations.
Trigger usage in general, and trigger-based migrations in particular, suffer from the following:
- Triggers, being stored routines, are interpreted code. MySQL does not precompile them. Hooking onto your query’s transaction space, they add the overhead of a parser and interpreter to each query acting on your migrated table.
-
Locks: the triggers share the same transaction space as the original queries, and while those queries compete for locks on the table, the triggers independently compete on locks on another table. This is in particular acute with the synchronous approach. Lock contention is directly related to write concurrency on the master. We have experienced near or complete lock downs in production, to the effect of rendering the table or the entire database inaccessible due to lock contention.
Another aspect of trigger locks is the metadata locks they require when created or destroyed. We’ve seen stalls to the extent of many seconds to a minute while attempting to remove triggers from a busy table at the end of a migration operation. - Non pausability: when load on the master turns high, you wish to throttle or suspend your pending migration. However a trigger-based solution cannot truly do so. While it may suspend the row-copy operation, it cannot suspend the triggers. Removal of the triggers results in data loss. Thus, the triggers must keep working throughout the migration. On busy servers, we have seen that even as the online operation throttles, the master is brought down by the load of the triggers.
- Concurrent migrations: we or others may be interested in being able to run multiple concurrent migrations (on different tables). Given the above trigger overhead, we are not prepared to run multiple concurrent trigger-based migrations. We are unaware of anyone doing so in practice.
- Testing: we might want to experiment with a migration, or evaluate its load. Trigger based migrations can only simulate a migration on replicas via Statement Based Replication, and are far from representing a true master migration given that the workload on a replica is single threaded (that is always the case on a per-table basis, regardless of multi-threaded replication technology in use).
gh-ost
gh-ost stands for GitHub’s Online Schema Transmogrifier/Transfigurator/Transformer/Thingy
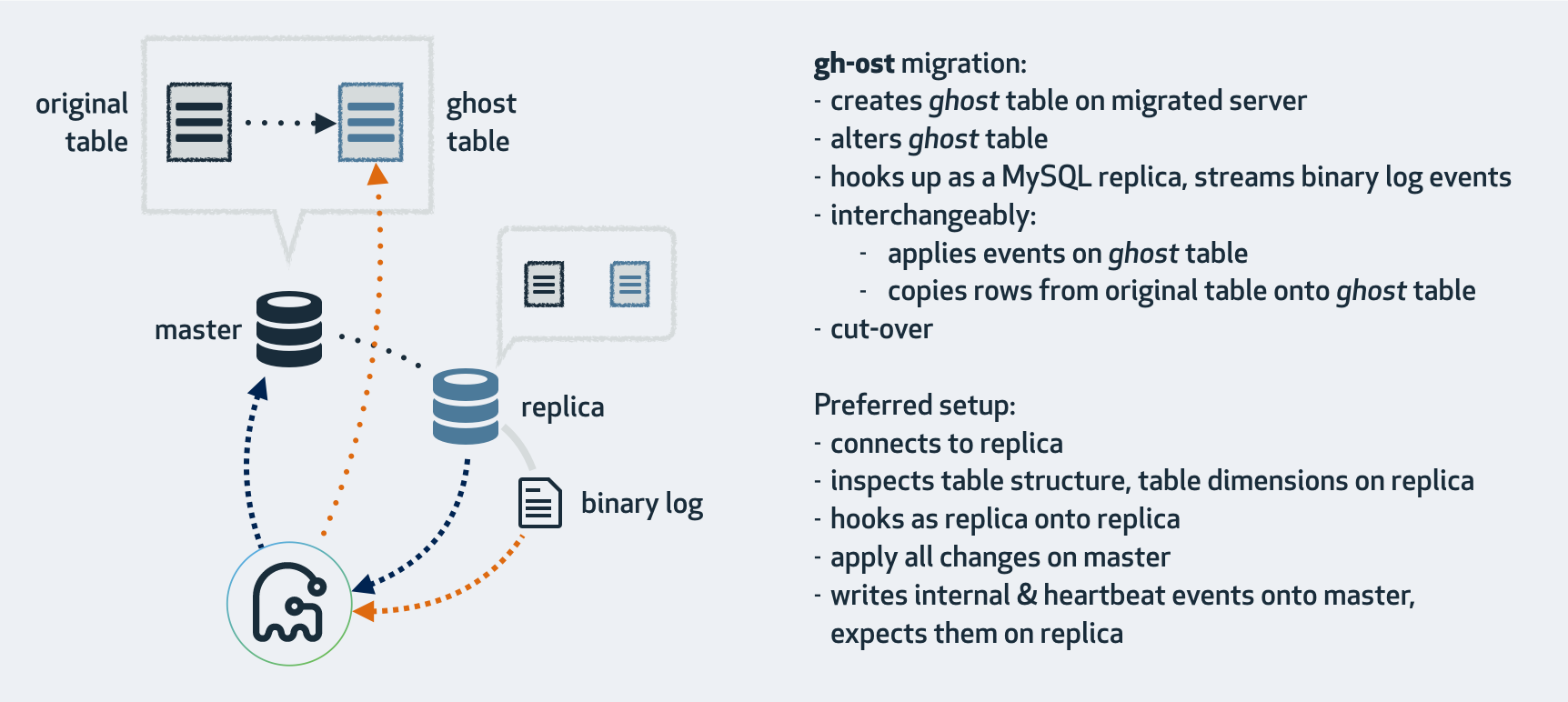
gh-ost is:
- Triggerless
- Lightweight
- Pauseable
- Dynamically controllable
- Auditable
- Testable
- Trustable
Triggerless
gh-ost does not use triggers. It intercepts changes to table data by tailing the binary logs. It therefore works in an asynchronous approach, applying the changes to the ghost table some time after they’ve been committed.
gh-ost expects binary logs in RBR (Row Based Replication) format; however that does not mean you cannot use it to migrate a master running with SBR (Statement Based Replication). In fact, we do just that. gh-ost is happy to read binary logs from a replica that translates SBR to RBR, and it is happy to reconfigure the replica to do that.
Lightweight
By not using triggers, gh-ost decouples the migration workload from the general master workload. It does not regard the concurrency and contention of queries running on the migrated table. Changes applied by such queries are streamlined and serialized in the binary log, where gh-ost picks them up to apply on the gh-ost table. In fact, gh-ost also serializes the row-copy writes along with the binary log event writes. Thus, the master only observes a single connection that is sequentially writing to the ghost table. This is not very different from ETLs.
Pauseable
Since all writes are controlled by gh-ost, and since reading the binary logs is an asynchronous operation in the first place, gh-ost is able to suspend all writes to the master when throttling. Throttling implies no row-copy on the master and no row updates. gh-ost does create an internal tracking table and keeps writing heartbeat events to that table even when throttled, in negligible volumes.
gh-ost takes throttling one step further and offers multiple controls over throttling:
-
Load: a familiar feature for users of
pt-online-schema-change, one may set thresholds on MySQL metrics, such asThreads_running=30 -
Replication lag:
gh-osthas a built-in heartbeat mechanism which it utilizes to examine replication lag; you may specify control replicas, orgh-ostwill implicitly use the replica you hook it to in the first place. -
Query: you may present with a query that decides if throttling should kick in. Consider
SELECT HOUR(NOW()) BETWEEN 8 and 17.All the above metrics can be dynamically changed even while the migration is executing.
-
Flag file: touch a file and
gh-ostbegins throttling. Remove the file and it resumes work. -
User command: dynamically connect to
gh-ost(see following) across the network and instruct it to start throttling.
Dynamically controllable
With existing tools, when a migration generates a high load, the DBA would reconfigure, say, a smaller chunk-size, terminate and re-run the migration from start. We find this wasteful.
gh-ost listens to requests via unix socket file and (configurable) via TCP. You may give gh-ost instructions even while migration is running. You may, for example:
-
echo throttle | socat - /tmp/gh-ost.sockto start throttling. Likewise you mayno-throttle - Change execution parameters:
chunk-size=1500,max-lag-millis=2000,max-load=Thread_running=30are examples to instructionsgh-ostaccepts that change its behavior.
Auditable
Likewise, the same interface can be used to ask gh-ost of the status. gh-ost is happy to report current progress, major configuration params, identity of servers involved and more. As this information is accessible via network, it gives great visibility into the ongoing operation, that you would otherwise find today only by using a shared screen or tailing log files.
Testable
Because the binary log content is decoupled from the master’s workload, applying a migration on a replica is more similar to a true master migration (though still not completely, and more work is on the roadmap).
gh-ost comes with built-in support for testing via --test-on-replica: it allows you to run a migration on a replica, such that at the end of the migration gh-ost would stop the replica, swap tables, reverse the swap, and leave you with both tables in place and in sync, replication stopped. This allows you to examine and compare the two tables at your leisure.
This is how we test gh-ost in production at GitHub: we have multiple designated production replicas; they are not serving traffic but instead running continuous covering migration test on all tables. Each of our production tables, as small as empty and as large as many hundreds of GB, is being migrated via a trivial statement that does not really modify its structure (engine=innodb). Each such migration ends with stopped replication. We take complete checksum of entire table data from both the original table and ghost table and expect them to be identical. We then resume replication and proceed to next table. Every single one of our production tables is known to have passed multiple successful migrations via gh-ost, on replica.
Trustable
All the above, and more, are made to build trust with gh-ost‘s operation. After all, it is a new tool in a landscape that has used the same tool for years.
-
We test
gh-oston replicas; we’ve completed thousands of successful migrations before trying it out on masters for the first time. So can you. Migrate your replicas, verify the data is intact. We want you to do that! -
As you execute
gh-ost, and as you may suspect load on your master is increasing, go ahead and initiate throttling. Touch a file.echo throttle. See how the load on your master is just back to normal. By just knowing you can do that, you will gain a lot of peace of mind. -
A migration begins and the ETA says it’s going to end at
2:00am? Are you concerned with the final cut-over, where the tables are swapped, and you want to stick around? You can instructgh-ostto postpone the cut-over using a flag file.gh-ostwill complete the row-copy but will not flip the tables. Instead, it will keep applying ongoing changes, keeping the ghost table in sync. As you come to the office the next day, remove the flag file orecho unpostponeintogh-ost, and the cut-over will be made. We don’t like our software to bind us into observing its behavior. It should instead liberate us to do things humans do. -
Speaking of ETA,
--exact-rowcountwill keep you smiling. Pay the initial price of a lengthySELECT COUNT(*)on your table.gh-ostwill get an accurate estimate of the amount of work it needs to do. It will heuristically update that estimation as migration proceeds. While ETA timing is always subject to change, progress percentage turns accurate. If, like us, you’ve been bitten by migrations stating99%then stalling for an hour keeping you biting your fingernails, you’ll appreciate the change.
gh-ost operation modes
gh-ost operates by connecting to potentially multiple servers, as well as connecting itself as a replica in order to stream binary log events directly from one of those servers. There are various operation modes, which depend on your setup, configuration, and where you want to run the migration.
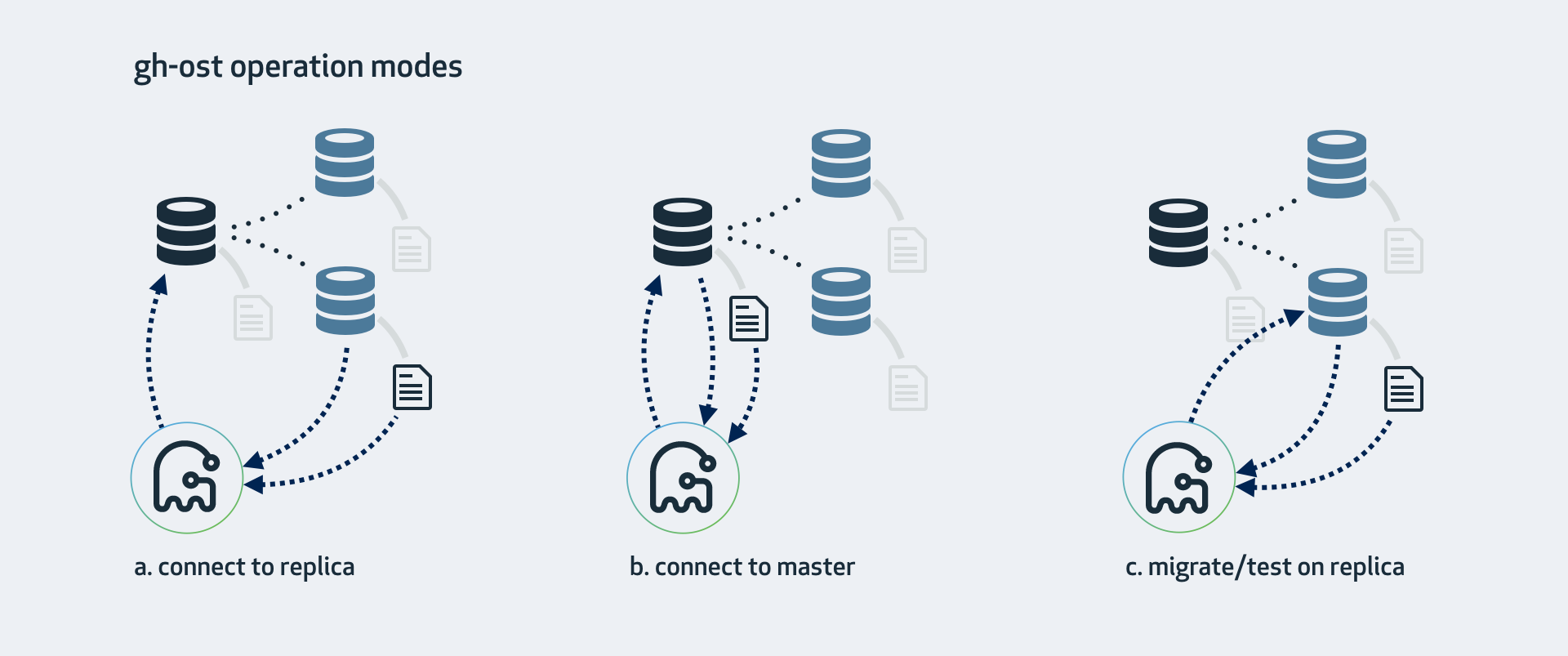
a. Connect to replica, migrate on master
This is the mode gh-ost expects by default. gh-ost will investigate the replica, crawl up to find the topology’s master, and connect to it as well. Migration will:
- Read and write row-data on master
- Read binary logs events on the replica, apply the changes onto the master
- Investigate table format, columns & keys, count rows on the replica
- Read internal changelog events (such as heartbeat) from the replica
- Cut-over (switch tables) on the master
If your master works with SBR, this is the mode to work with. The replica must be configured with binary logs enabled (log_bin, log_slave_updates) and should have binlog_format=ROW (gh-ost can apply the latter for you).
However even with RBR we suggest this is the least master-intrusive operation mode.
b. Connect to master
If you don’t have replicas, or do not wish to use them, you are still able to operate directly on the master. gh-ost will do all operations directly on the master. You may still ask it to be considerate of replication lag.
- Your master must produce binary logs in RBR format.
- You must approve this mode via
--allow-on-master.
c. Migrate/test on replica
This will perform a migration on the replica. gh-ost will briefly connect to the master but will thereafter perform all operations on the replica without modifying anything on the master.
Throughout the operation, gh-ost will throttle such that the replica is up to date.
-
--migrate-on-replicaindicates togh-ostthat it must migrate the table directly on the replica. It will perform the cut-over phase even while replication is running. -
--test-on-replicaindicates the migration is for purpose of testing only. Before cut-over takes place, replication is stopped. Tables are swapped and then swapped back: your original table returns to its original place.
Both tables are left with replication stopped. You may examine the two and compare data.
gh-ost at GitHub
gh-ost is now powering all of our production migrations. We’re running it daily, as engineering requests come, sometimes multiple times a day. With its auditing and control capabilities, we will be integrating it into our chatops. Our engineers will have clear insight into migration progress and will be able to control its behavior. Metrics and events are being collected and will provide with clear visibility into migration operations in production.
Open source
gh-ost is released with to the open source community under the MIT license.
While we find it to be stable, we have improvements we want to make. We release it at this time as we wish to welcome community participation and contributions. From time to time we may publish suggestions for community contributions.
gh-ost is actively maintained. We encourage you to try it out, test it; we’ve made great efforts to make it trustworthy.
Acknowledgements
gh-ost is designed, developed, reviewed and tested by the database infrastructure engineering team at GitHub:
@jonahberquist, @ggunson, @tomkrouper, @shlomi-noach
We would like to acknowledge the engineers at GitHub who have provided valuable information and advice. Thank you to our friends from the MySQL community who have reviewed and commented on this project during its pre-production stages.
Written by

Related posts

GitHub availability report: June 2026
In June, we experienced six incidents that resulted in degraded performance across GitHub services.

Q1 2026 Innovation Graph update: Open source collaboration is accelerating worldwide
New Innovation Graph data shows global developer communities growing faster than ever, with collaboration reaching new highs across many economies.
GitHub joins coalition advocating for fixes to California AI Transparency Act to protect open source
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.