Rearchitecting GitHub Pages
GitHub Pages, our static site hosting service, has always had a very simple architecture. From launch up until around the beginning of 2015, the entire service ran on a single…
GitHub Pages, our static site hosting service, has always had a very simple architecture. From launch up until around the beginning of 2015, the entire service ran on a single pair of machines (in active/standby configuration) with all user data stored across 8 DRBD backed partitions. Every 30 minutes, a cron job would run generating an nginx map file mapping hostnames to on-disk paths.
There were a few problems with this approach: new Pages sites did not appear until the map was regenerated (potentially up to a 30-minute wait!); cold nginx restarts would take a long time while nginx loaded the map off disk; and our storage capacity was limited by the number of SSDs we could fit in a single machine.
Despite these problems, this simple architecture worked remarkably well for us — even as Pages grew to serve thousands of requests per second to over half a million sites.
When we started approaching the storage capacity limits of a single pair of machines and began to think about what a rearchitected GitHub Pages would look like, we made sure to stick with the same ideas that made our previous architecture work so well: using simple components that we understand and avoiding prematurely solving problems that aren’t yet problems.
The new infrastructure
The new Pages infrastructure has been in production serving Pages requests since January 2015 and we thought we’d share a little bit about how it works.
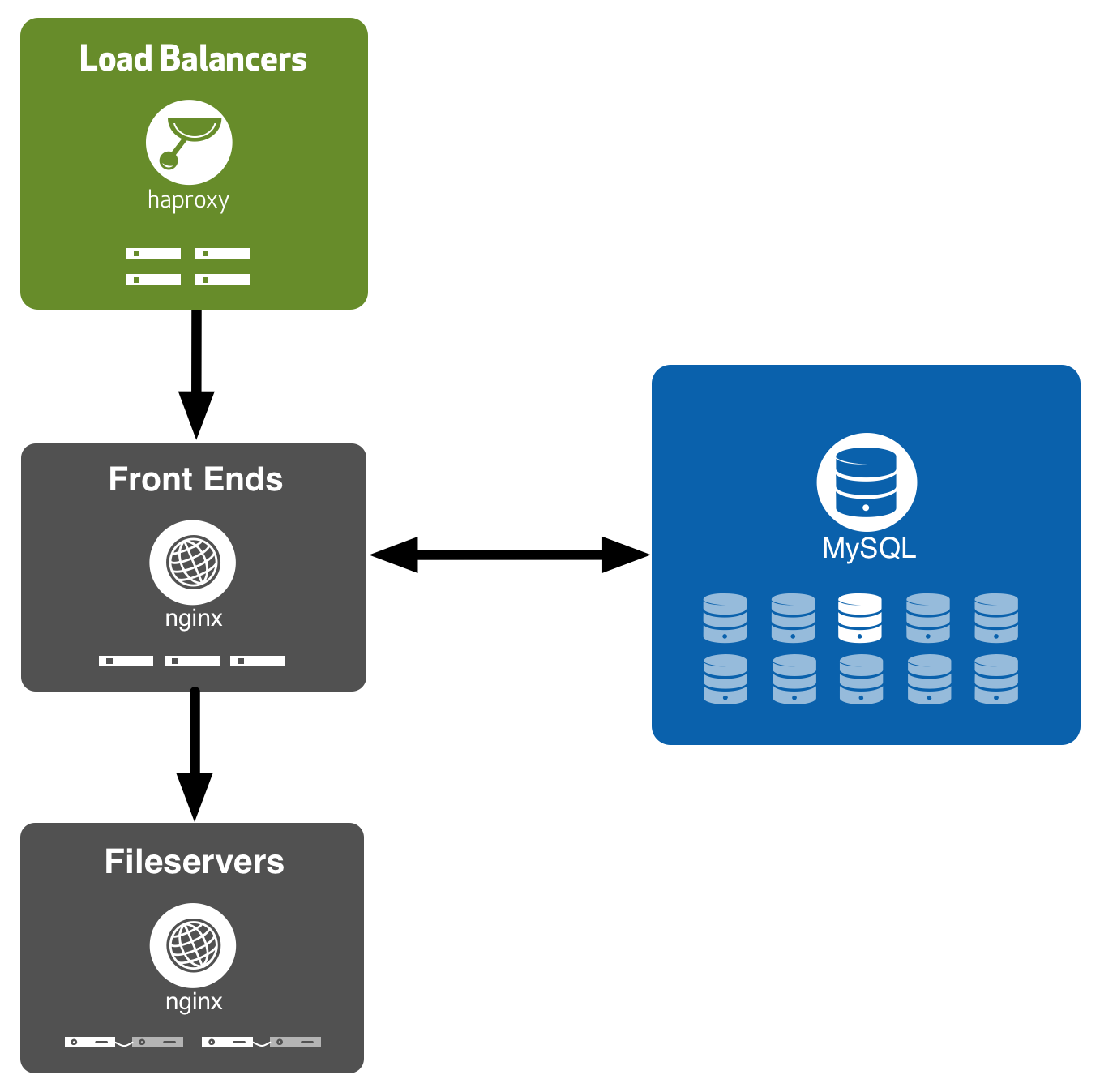
Frontend tier
After making it through our load balancers, incoming requests to Pages hit our frontend routing tier. This tier comprises a handful of Dell C5220s running nginx. An ngx_lua script looks at the incoming request and makes a decision about which fileserver to route it to. This involves querying one of our MySQL read replicas to look up which backend storage server pair a Pages site has been allocated to.
Once our Lua router has made a routing decision, we just use nginx’s stock proxy_pass feature to proxy back to the fileserver. This is where ngx_lua’s integration with nginx really shines, as our production nginx config is not much more complicated than:
location / {
set $gh_pages_host "";
set $gh_pages_path "";
access_by_lua_file /data/pages-lua/router.lua;
proxy_set_header X-GitHub-Pages-Root $gh_pages_path;
proxy_pass http://$gh_pages_host$request_uri;
}One of the major concerns we had with querying MySQL for routing is that this introduces an availability dependency on MySQL. This means that if our MySQL cluster is down, so is GitHub Pages. The reliance on external network calls also adds extra failure modes — MySQL queries performed over the network can fail in ways that a simple in-memory hashtable lookup cannot.
This is a tradeoff we accepted, but we have mitigations in place to reduce user impact if we do have issues. If the router experiences any error during a query, it’ll retry the query a number of times, reconnecting to a different read replica each time. We also use ngx_lua’s shared memory zones to cache routing lookups on the pages-fe node for 30 seconds to reduce load on our MySQL infrastructure and also allow us to tolerate blips a little better.
Since we’re querying read replicas, we can tolerate downtime or failovers of the MySQL master. This means that existing Pages will remain online even during database maintenance windows where we have to take the rest of the site down.
We also have Fastly sitting in front of GitHub Pages caching all 200 responses. This helps minimise the availability impact of a total Pages router outage. Even in this worst case scenario, cached Pages sites are still online and unaffected.
Fileserver tier
The fileserver tier consists of pairs of Dell R720s running in active/standby configuration. Each pair is largely similar to the single pair of machines that the old Pages infrastructure ran on. In fact, we were even able to reuse large parts of our configuration and tooling for the old Pages infrastructure on these new fileserver pairs due to this similarity.
We use DRBD to sync Pages site data between the two machines in each pair. DRBD lets us synchronously replicate all filesystem changes from the active machine to the standby machine, ensuring that the standby machine is always up to date and ready to take over from the active at a moment’s notice — say for example if the active machine crashes or we need to take it down for maintenance.
We run a pretty simple nginx config on the fileservers too – all we do is set the document root to $http_x_github_pages_root (after a little bit of validation to thwart any path traversal attempts, of course) and the rest just works.
Wrapping up
Not only are we now able to scale out our storage tier horizontally, but since the MySQL routing table is kept up to date continuously, new Pages sites are published instantly rather than 30 minutes later. This is a huge win for our customers. The fact that we’re no longer loading a massive pre-generated routing map when nginx starts also means the old infrastructure’s cold-restart problem is no longer an issue.
We’ve also been really pleased with how ngx_lua has worked out. Its performance has been excellent — we spend less than 3ms of each request in Lua (including time spent in external network calls) at the 98th percentile across millions of HTTP requests per hour. The ability to embed our own code into nginx’s request lifecycle has also meant that we’re able to reuse nginx’s rock-solid proxy functionality rather than reinventing that particular wheel on our own.
Written by

Related posts
GitHub joins coalition advocating for fixes to California AI Transparency Act to protect open source
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.

GitHub availability report: May 2026
In May, we experienced nine incidents that resulted in degraded performance across GitHub services.

GitHub Universe is back: All together now, in the agentic era
GitHub Universe is back: returning to the historic Fort Mason Center in San Francisco on October 28–29, 2026.