Making MySQL Better at GitHub
At GitHub we say, “it’s not fully shipped until it’s fast.” We’ve talked before about some of the ways we keep our frontend experience speedy, but that’s only part of…
At GitHub we say, “it’s not fully shipped until it’s fast.” We’ve talked before about some of the ways we keep our frontend experience speedy, but that’s only part of the story. Our MySQL database infrastructure dramatically affects the performance of GitHub.com. Here’s a look at how our infrastructure team seamlessly conducted a major MySQL improvement last August and made GitHub even faster.
The mission
Last year we moved the bulk of GitHub.com’s infrastructure into a new datacenter with world-class hardware and networking. Since MySQL forms the foundation of our backend systems, we expected database performance to benefit tremendously from an improved setup. But creating a brand-new cluster with brand-new hardware in a new datacenter is no small task, so we had to plan and test carefully to ensure a smooth transition.
Preparation
A major infrastructure change like this requires measurement and metrics gathering every step of the way. After installing base operating systems on our new machines, it was time to test out our new setup with various configurations. To get a realistic test workload, we used tcpdump to extract SELECT queries from the old cluster that was serving production and replayed them onto the new cluster.
MySQL tuning is very workload specific, and well-known configuration settings like innodb_buffer_pool_size often make the most difference in MySQL’s performance. But on a major change like this, we wanted to make sure we covered everything, so we took a look at settings like innodb_thread_concurrency, innodb_io_capacity, and innodb_buffer_pool_instances, among others.
We were careful to only make one test configuration change at a time, and to run tests for at least 12 hours. We looked for query response time changes, stalls in queries per second, and signs of reduced concurrency. We observed the output of SHOW ENGINE INNODB STATUS, particularly the SEMAPHORES section, which provides information on work load contention.
Once we were relatively comfortable with configuration settings, we started migrating one of our largest tables onto an isolated cluster. This served as an early test of the process, gave us more space in the buffer pools of our core cluster and provided greater flexibility for failover and storage. This initial migration introduced an interesting application challenge, as we had to make sure we could maintain multiple connections and direct queries to the correct cluster.
In addition to all our raw hardware improvements, we also made process and topology improvements: we added delayed replicas, faster and more frequent backups, and more read replica capacity. These were all built out and ready for go-live day.
Making a list; checking it twice
With millions of people using GitHub.com on a daily basis, we did not want to take any chances with the actual switchover. We came up with a thorough checklist before the transition:
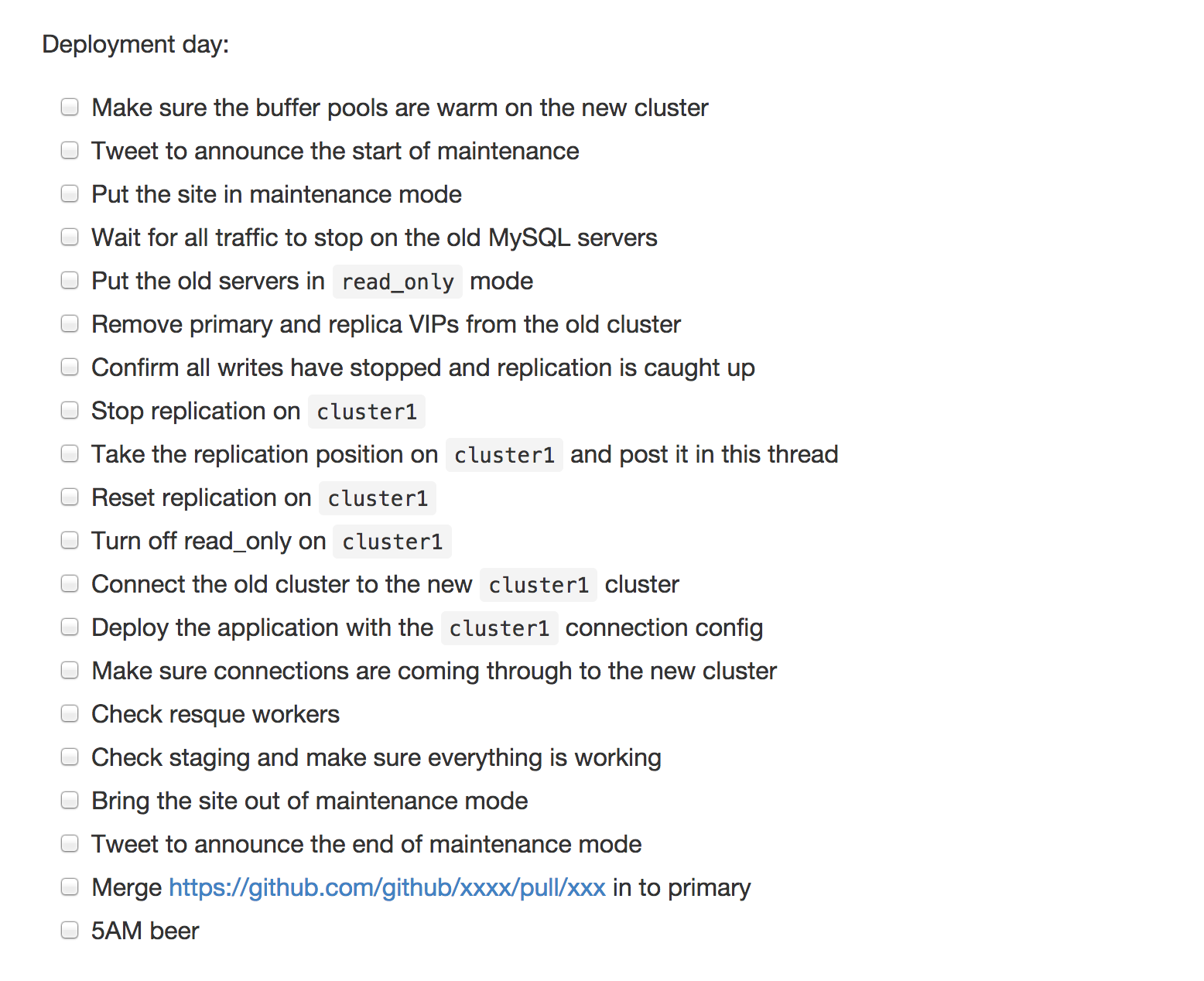
We also planned a maintenance window and announced it on our blog to give our users plenty of notice.
Migration day
At 5am Pacific Time on a Saturday, the migration team assembled online in chat and the process began:
We put the site in maintenance mode, made an announcement on Twitter, and set out to work through the list above:
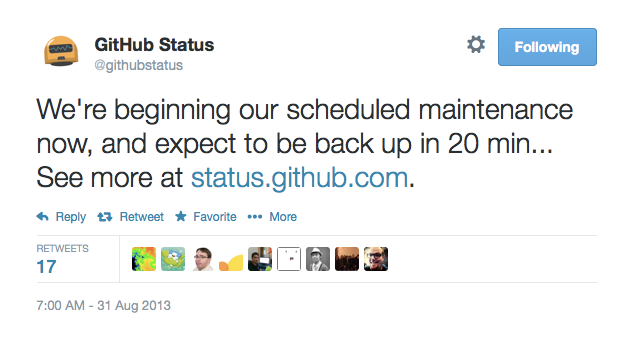
13 minutes later, we were able to confirm operations of the new cluster:

Then we flipped GitHub.com out of maintenance mode, and let the world know that we were in the clear.
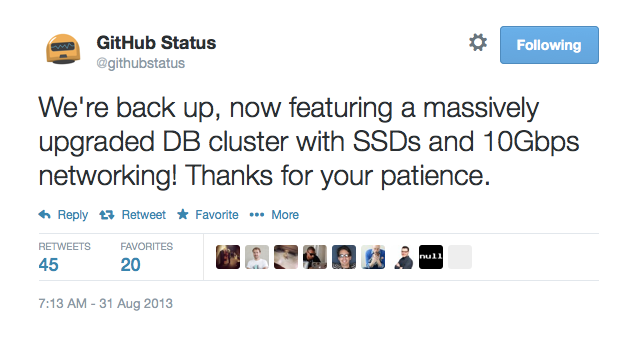
Lots of up front testing and preparation meant that we kept the work we needed on go-live day to a minimum.
Measuring the final results
In the weeks following the migration, we closely monitored performance and response times on GitHub.com. We found that our cluster migration cut the average GitHub.com page load time by half and the 99th percentile by two-thirds:
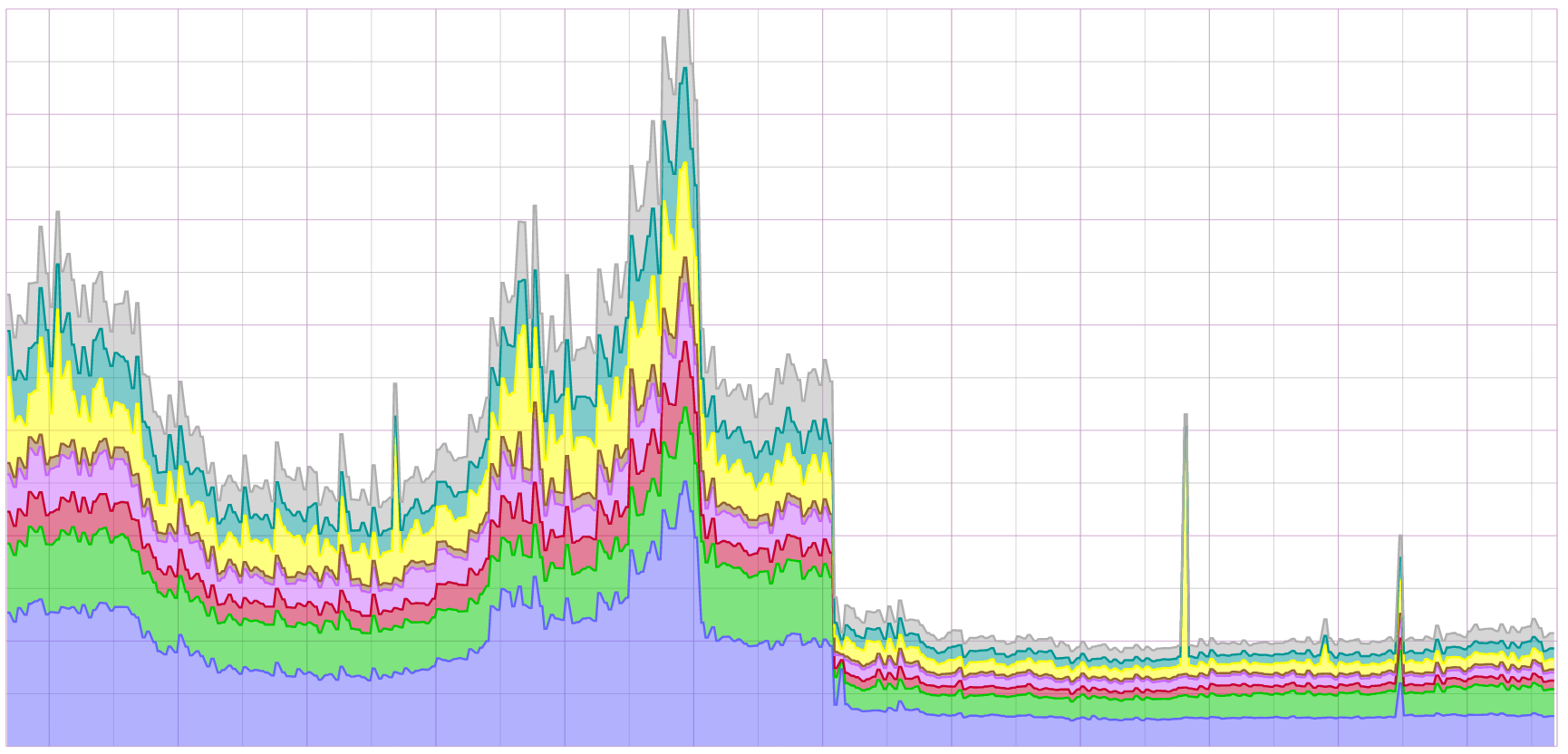
What we learned
Functional partitioning
During this process we decided that moving larger tables that mostly store historic data to separate cluster was a good way to free up disk and buffer pool space. This allowed us to leave more resources for our “hot” data, splitting some connection logic to enable the application to query multiple clusters. This proved to be a big win for us and we are working to reuse this pattern.
Always be testing
You can never do too much acceptance and regression testing for your application. Replicating data from the old cluster to the new cluster while running acceptance tests and replaying queries were invaluable for tracing out issues and preventing surprises during the migration.
The power of collaboration
Large changes to infrastructure like this mean a lot of people need to be involved, so pull requests functioned as our primary point of coordination as a team. We had people all over the world jumping in to help.
Deploy day team map:
This created a workflow where we could open a pull request to try out changes, get real-time feedback, and see commits that fixed regressions or errors — all without phone calls or face-to-face meetings. When everything has a URL that can provide context, it’s easy to involve a diverse range of people and make it simple for them give feedback.
One year later..
A full year later, we are happy to call this migration a success — MySQL performance and reliability continue to meet our expectations. And as an added bonus, the new cluster enabled us to make further improvements towards greater availability and query response times. I’ll be writing more about those improvements here soon.
Written by

Related posts

GitHub availability report: June 2026
In June, we experienced six incidents that resulted in degraded performance across GitHub services.

Q1 2026 Innovation Graph update: Open source collaboration is accelerating worldwide
New Innovation Graph data shows global developer communities growing faster than ever, with collaboration reaching new highs across many economies.
GitHub joins coalition advocating for fixes to California AI Transparency Act to protect open source
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.