Deploying at GitHub
Deploying is a big part of the lives of most GitHub employees. We don’t have a release manager and there are no set weekly deploys. Developers and designers are responsible…
Deploying is a big part of the lives of most GitHub employees. We don’t have a release manager and there are no set weekly deploys. Developers and designers are responsible for shipping new stuff themselves as soon as it’s ready. This means that deploying needs to be as smooth and safe a process as possible.
The best system we’ve found so far to provide this flexibility is to have people deploy branches. Changes never get merged to master until they have been verified to work in production from a branch. This means that master is always stable; a safe point that we can roll back to if there’s a problem.
The basic workflow goes like this:
- Push changes to a branch
- Wait for the build to pass on our CI server
- Tell Hubot to deploy it
- Verify that the changes work and fix any problems that come up
- Merge the branch into master
Not too long ago, however, this system wasn’t very smart. A branch could accidentally be deployed before the build finished, or even if the build failed. Employees could mistakenly deploy over each other. As the company has grown, we’ve needed to add some checks and balances to help us prevent these kinds of mistakes.
Safety First
The first thing we do now, when someone tries to deploy, is make a call to Janky to determine whether the current CI build is green. If it hasn’t finished yet or has failed, we’ll tell the deployer to fix the situation and try again.
Next we check whether the application is currently “locked”. The lock indicates that a particular branch is being deployed in production and that no other deploys of the application should proceed for the moment. Successful builds on the master branch would otherwise get deployed automatically, so we don’t want those going out while a branch is being tested. We also don’t want another developer to accidentally deploy something while the branch is out.
The last step is to make sure that the branch we’re deploying contains the latest commit on master that has made it into production. Once a commit on master has been deployed to production, it should never be “removed” from production by deploying a branch that doesn’t have that commit in it yet.
We use the GitHub API to verify this requirement. An endpoint on the github.com application exposes the SHA1 that is currently running in production. We submit this to the GitHub compare API to obtain the “merge base”, or the common ancestor, of master and the production SHA1. We can then compare this to the branch that we’re attempting to deploy to check that the branch is caught up. By using the common ancestor of master and production, code that only exists on a branch can be removed from production, and changes that have landed on master but haven’t been deployed yet won’t require branches to merge them in before deploying.
If it turns out the branch is behind, master gets merged into it automatically. We do this using the new
At this point the code actually gets deployed to our servers. We usually deploy to all servers for consistency, but a subset of servers can be specified if necessary. This subset can be by functional role — front-end, file server, worker, search, etc. — or we can specify an individual machine by name, e.g, ‘fe7’.
Watch it in action
What now? It depends on the situation, but as a rule of thumb, small to moderate changes should be observed running correctly in production for at least 15 minutes before they can be considered reasonably stable. During this time we monitor exceptions, performance, tweets, and do any extra verification that might be required. If non-critical tweaks need to be made, changes can be pushed to the branch and will be deployed automatically. In the event that something bad happens, rolling back to master only takes 30 seconds.
All done!
If everything goes well, it’s time to merge the changes. At GitHub, we use Pull Requests for almost all of our development, so merging typically happens through the pull request page. We detect when the branch gets merged into master and unlock the application. The next deployer can now step up and ship something awesome.
How do we do it?
Most of the magic is handled by an internal deployment service called Heaven. At its core, Heaven is a catalog of Capistrano recipes wrapped up in a Sinatra application with a JSON API. Many of our applications are deployed using generic recipes, but more complicated apps can define their own to specify additional deployment steps. Wiring it up to Janky, along with clever use of post-receive hooks and the GitHub API, lets us hack on the niceties over time. Hubot is the central interface to both Janky and Heaven, giving everyone in Campfire great visibility into what’s happening all of the time. As of this writing, 75 individual applications are deployed by Heaven.
Always be shipping
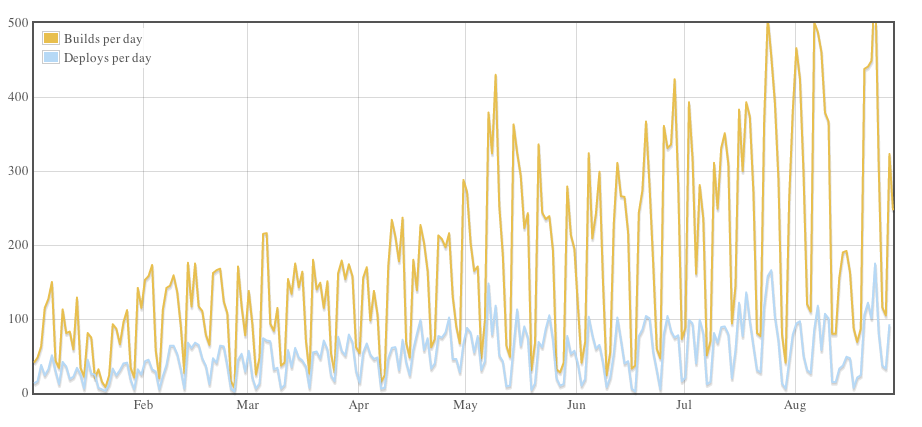
Not all projects at GitHub use this workflow, which is core to github.com development, but here are a couple of stats for build and deploy activity company-wide so far in 2012:
- 41,679 builds
- 12,602 deploys
- The lull in mid-August was our company summit, which kicked off the following week with a big dose of inspiration. Our busiest day yet, Aug. 23, saw 563 builds and 175 deploys.
Written by

Related posts

GitHub availability report: June 2026
In June, we experienced six incidents that resulted in degraded performance across GitHub services.

Q1 2026 Innovation Graph update: Open source collaboration is accelerating worldwide
New Innovation Graph data shows global developer communities growing faster than ever, with collaboration reaching new highs across many economies.
GitHub joins coalition advocating for fixes to California AI Transparency Act to protect open source
We’re calling for targeted amendments to resolve conflicts with open source licensing and align with international transparency frameworks while preserving regulatory intent.