Nodeload2: Downloads Reloaded
Nodeload, the first GitHub node.js project, turned 1 year old recently. Nodeload is what prepares git repository contents into zip and tarballs. As the service has grown over the last…
Nodeload, the first GitHub node.js project, turned 1 year old recently. Nodeload is what prepares git repository contents into zip and tarballs. As the service has grown over the last year, we’ve been running into various issues. Read about Nodeload’s origin if you don’t remember why it works the way it works now.
Essentially, we have too many requests flowing through the single nodeload server. These requests were spawning git archive processes, which spawn ssh processes to communicate with the file servers. These requests are constantly writing gigabytes of data, and serving them through nginx. One simple idea was to order more servers, but that would create a duplicate cache of archived repositories. I wanted to avoid that if possible. So, I decided to start over and rewrite Nodeload from scratch.
Now, the Nodeload server only runs a simple proxy app. This proxy app looks up the appropriate file servers for a repo, and proxies the data directly from the file server. The file servers now run an archiver app that’s basically an HTTP frontend over git archive. Cached repositories are now written to an in-memory tmpfs partition to keep the disk IO down. The Nodeload proxy also tries the backup fileservers before the active fileservers, shifting a lot of the load to the underutilized backups.
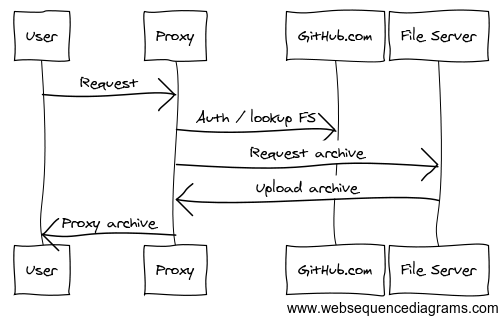
Node.js makes a pretty great fit for this app due to the beautiful stream API. When implementing a proxy of any kind, you have to deal with clients that can’t read content as fast as you can send it. When an HTTP server response stream can’t send any more data to you, write() returns false. Then, you can pause the proxied HTTP request stream, until the server response emits a drain event. The drain event means it’s ready to send more data, and that you can now resume the proxied HTTP request stream. This logic is all encapsulated in the ReadableStream.pipe() function.
// proxy the file stream to the outgoing HTTP response
var reader = fs.createReadStream('some/file')
reader.pipe(res)Rocky Launch
After launching, we ran into some strange issues over the weekend:
- The Nodeload servers still had high IO.
- Backup file servers were running out of memory.
- Nodeload servers were running out of memory.
topandpsshowed no nodeload processes ballooning in size. Nodeload looked fine (at a cool 30-50MB RSS), but we could watch the server’s available memory slowly drop.
We tracked the high IO down to the nginx proxy_buffering option. Once we disabled that, IO dropped. This means that the streams move at the speed of the client. If they can’t download the archive fast enough, the proxy pauses the HTTP request stream. This passes through to the archiver app, which pauses the file stream.
For the memory leak, I tried installing v8-profiler (including Felix Gnass’ patch for showing heap retainers), and used node-inspector to watch the live node process in production. Using Webkit Web Inspector to profile the app is amazing, but it didn’t point to any obvious memory leaks.
At this point, @tmm1, @rtomayko, and @rodjek jumped in to help brainstorm other possible problems. They eventually tracked down the leak to fd’s accumulating on the processes.
tmm1@arch1:~$ sudo lsof -nPp 17655 | grep ":7005 ("
node 17655 git 16u IPv4 8057958 TCP 172.17.1.40:49232->172.17.0.148:7005 (ESTABLISHED)
node 17655 git 21u IPv4 8027784 TCP 172.17.1.40:38054->172.17.0.133:7005 (ESTABLISHED)
node 17655 git 22u IPv4 8058226 TCP 172.17.1.40:42498->172.17.0.134:7005 (ESTABLISHED)It turns out that the reader streams were not being properly closed when clients were aborting the download. This was causing fd’s to stay open on the Nodeload server, as well as the file servers. This actually caused Nagios to warn us of full /data/archives partitions, when there was only 20MB of archives in there. The opened fd’s prevented the server from reclaiming space from the purged archive caches.
The fix for this was watching for the ‘close’ event on the HTTP server request. pipe() doesn’t really handle this because it’s written for the generic Readable stream API. The ‘close’ event is different than the common ‘end’ event, because it means the HTTP request stream was terminated before response.end() could be called.
// check to see if the request is closed already
if(req.connection.destroyed)
return
var reader = fs.createReadStream('/some/file')
req.on('close', function() {
reader.destroy()
})
reader.pipe(res)Conclusion
Nodeload is now more stable than it’s been in awhile. The rewritten code is simpler and better tested than before. Node.js is working out just fine. But, the fact that we’re using HTTP everywhere means we can replace either component easily. Our main job now is to setup better metrics to watch Nodeload and improve the reliability of the service.
Written by

Related posts

From pair to peer programmer: Our vision for agentic workflows in GitHub Copilot
AI agents in GitHub Copilot don’t just assist developers but actively solve problems through multi-step reasoning and execution. Here’s what that means.
GitHub Availability Report: May 2025
In May, we experienced three incidents that resulted in degraded performance across GitHub services.

GitHub Universe 2025: Here’s what’s in store at this year’s developer wonderland
Sharpen your skills, test out new tools, and connect with people who build like you.